Introduction
Firm collapse prediction has been a subject of interests for almost a century and it still ranks high among hottest topics in economics. The aim of predicting financial distress is to develop a predictive model that combines various econometric measures and allows to foresee a financial condition of a firm. The purpose of the bankruptcy prediction is to assess the financial condition of a company and its future perspectives within the context of long term operation on the market.
Data Processing – Sample, Explore, Modify
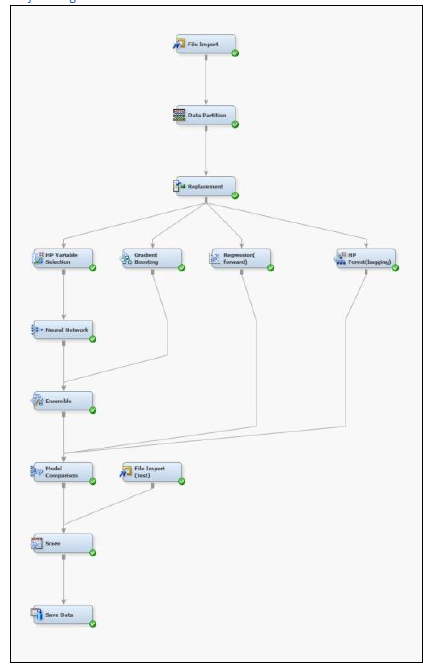
We commence our data processing by using File Import Node to fetch the training data. For the purpose of data modelling, we divide our dataset into Training and Validation set using Data Partition Node. The input data was divided into a 80% training set and 20% validation set, for us to train and validate our models.
Originally, the dataset had 64 predictor variables. We have connected the data partition node to a High-Performance Variable Selection node that lists predictor variables in order of their worth or the level of influence on the target variable. The HP variable selection node sets the variable status = ‘Rejected’ for the predictors that do not have much effect on the target variable relatively. The variables that are useful for predicting the target variables retain their status = ‘Input’. The rejected variables are not used as model inputs by a successor modeling node attached to this HP Variable Selection node. In our analysis, the data exported from the HP Variable selection node comprised of 33 inputs and 31 of the initial predictor variables are rejected.
Model Building
HP Forest & Gradient Boosting
Two of our models – HP Forest (using a Bagging approach) and Gradient Boosting are directly connected to the Data Partition node. For each of these nodes, parameters such as number of iterations (boosting) and maximum number of trees (HP Forest) were tuned and set at an optimal that minimizes the misclassification rate.
Forward Logistic Regression
To further explore the relationship between variables, we employed the forward regression model, which begins with an empty model and adds in variables one by one. The model adds one variable that gives the single best improvement to the model. We used this node with its default setting.
Neural Network
With respect to forth model – Neural Network is connected to the output of the HP Variable Selection node. The thought process behind feeding it a lesser number of predictors was to allow for maximum efficiency and minimal computation time of neural network for a larger number of iterations.
Ensemble Model
Finally, our last model involves making use of the Ensemble node. This creates a combined model using the posterior probabilities for class targets. This helps in improving the stability of different non-linear models like the neural network. All the default parameters were made us of for this node.
Project Diagram
Model Assesment
